前提
JINS-MEME という製品があります
jinsmeme.com
かけているだけで生体データを取得して活動量や精神状態などを分析してくれるすぐれものです
ダッシュボードを備えたスマホアプリが公式で提供されていますが、実は JINS-MEME には Web API があってここから自分のデータをCSV形式で取得できます
jins-meme.github.io
三連休で暇なので Web API 経由で自分のデータを取得して R で分析してみました
公式から JINS-MEME のデータを使った分析例が提供されていますが、これは Python で書かれているので R でやり直してみます
今回試してみたのは頭部運動回数を週ごとに分析した例で公式のドキュメント を参考に試行錯誤して R で実装してみました
まずはデータの取得からですが、私の場合自作のパッケージを使って取得したデータを Bigquery に上げているのでここから取得するようにしています
query <- "SELECT * FROM `my-health-dataset.jins_meme.60s_interval_data`"
tb <- bq_project_query(project, query)
df <- bq_table_download(tb)
df <- as_tibble(df)
ダウンロードした後は文字列型で保存されているタイムスタンプを日付型に変換し、そこから week number を抜き出します
R には lubridate::week という便利な関数があるのでこの処理は1行で書くことができます
df <- df %>%
mutate(
timestamp = as.Date(date),
week = week(timestamp)
)
続いてチュートリアルでもあったようにデータのフィルタリングを行います
df <- df %>%
filter(wea_s >= 20, tl_yav >= -45, tl_yav <= 90, tl_xav >= -45, tl_xav <= 45)
まずは週ごとの累積密度分布を書いてみました
df %>%
ggplot(aes(x = hm_yo, color=as.factor(week))) +
stat_ecdf(geom = "step") +
scale_x_log10() +
labs(title = "Cumulative Histogram of Head Movement (Yaw) by Week",
x = "headMoveHorizontalCount (log)",
y = "density")
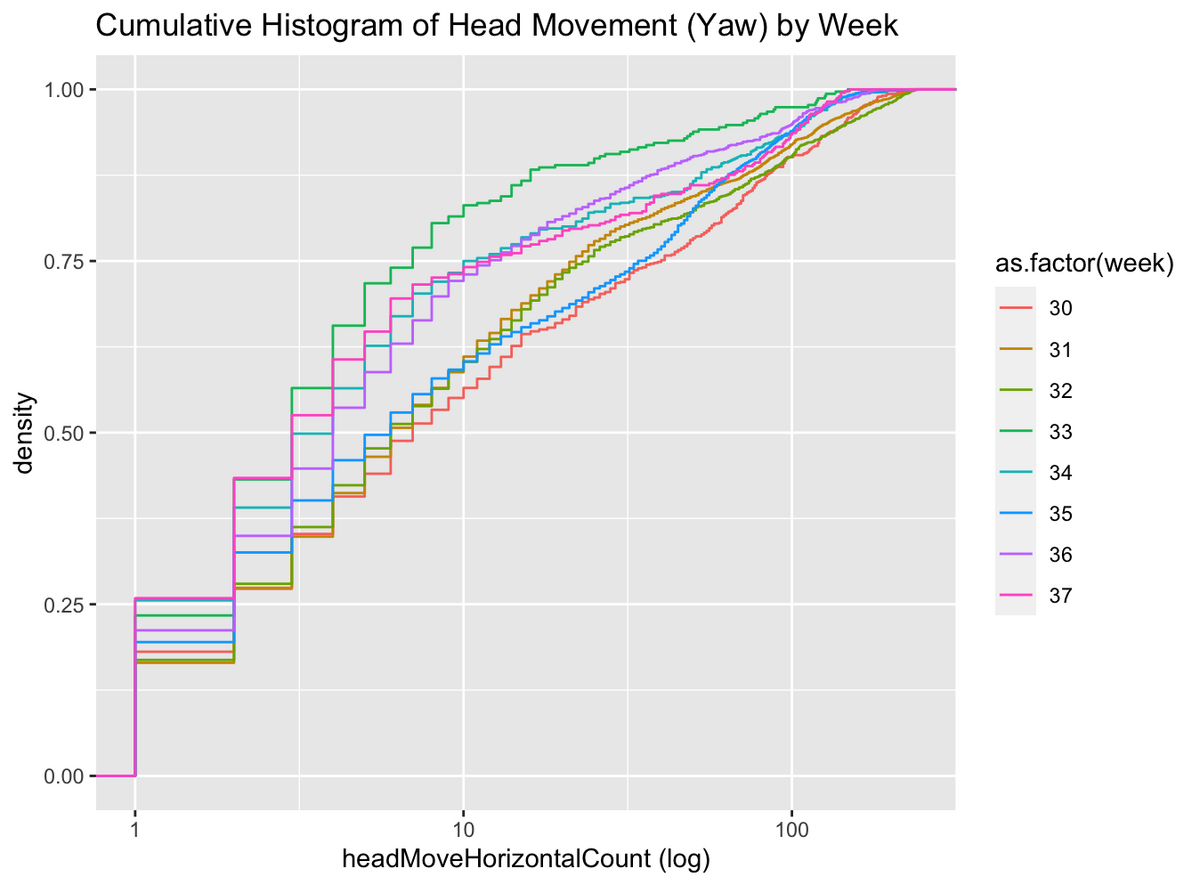
これだけだとなんじゃこれという感じですが、対数プロットで直線になっているので、見る人が見ると頭部回転運動の回数は冪乗分布であることがわかります
なのでチュートリアルにもあるように、この場合は平均を取る代わりに 90 パーセンタイル点をとって、週ごとに比較してみます
df %>%
group_by(week) %>%
summarise(
hm_yo_90 = quantile(hm_yo, 0.9)
) %>%
ggplot(aes(x = week, y = hm_yo_90)) +
geom_line() +
labs(title = "90% Quantile of Head Movement (Yaw) by Week",
x = "week",
y = "headMoveHorizontalCount")
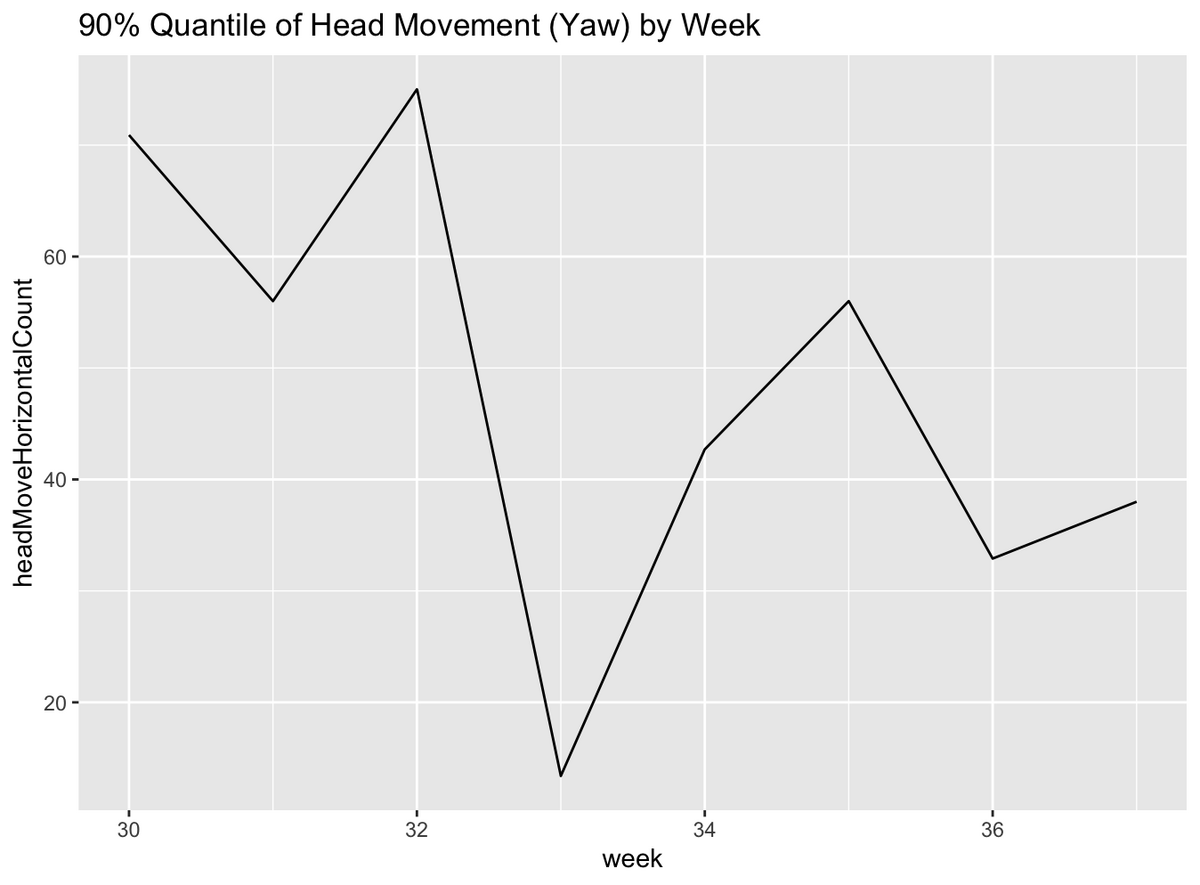
僕一人のデータだけだと特に何がわかるというわけでもないんですけど、チュートリアルにもあるように、他の人のデータと比べるとその人の活動量の大きさがわかるかもしれません
集中度の分析
チュートリアルで分析した頭部回転運動は指標として少し味気ないので、次に多少意味のある指標として JINS MEME から得られる「集中度」を時間ごとに分析してみたいと思います
公式のドキュメントによると「集中度」というのは
まばたき間隔平均値を利用し「ある一つのタスクへの注意が続いている状態」を指標化しています
とのことでおそらく、まばたき間隔が長くなると集中度が高いと判定されるものだと思われます
スコアは0-100の間で表されスコアが高いほど集中度が高いと判定されたことを意味します
集中度のデータは15秒ごとのデータになるので今回は 15s_interval_data というテーブルを読み込みます
また今回は時間ごとに分析したかったので week のほかに hour も変数に追加します
query <- "SELECT * FROM `my-health-dataset.jins_meme.15s_interval_data`"
tb <- bq_project_query(project, query)
df <- bq_table_download(tb)
df <- as_tibble(df)
df <- df %>%
mutate(
timestamp = as_datetime(date),
hour = hour(timestamp) + 9,
week = week(timestamp)
)
仕事中の集中度を比較したいので、勤務時間中のログのみを吸い出します
df.work = df %>%
filter(vld == TRUE, hour >= 10, hour <= 19, tl_yav >= -45, tl_yav <= 90, tl_xav >= -45, tl_xav <= 45)
hour, week ごとに集中度の 50 パーセンタイル点を抜き出す
df.work.summary = df.work %>%
group_by(hour, week) %>%
summarise(
sc_fcs_50 = quantile(sc_fcs, 0.5)
)
いざ、プロット
df.work.summary %>%
ggplot(aes(x = hour, y = sc_fcs_50, color=as.factor(week))) +
geom_smooth(se=FALSE) +
scale_x_continuous(breaks = seq(10, 19, 1)) +
labs(title = "50% Quantile of Focus Score by Hour",
x = "hour",
y = "Focus Score")
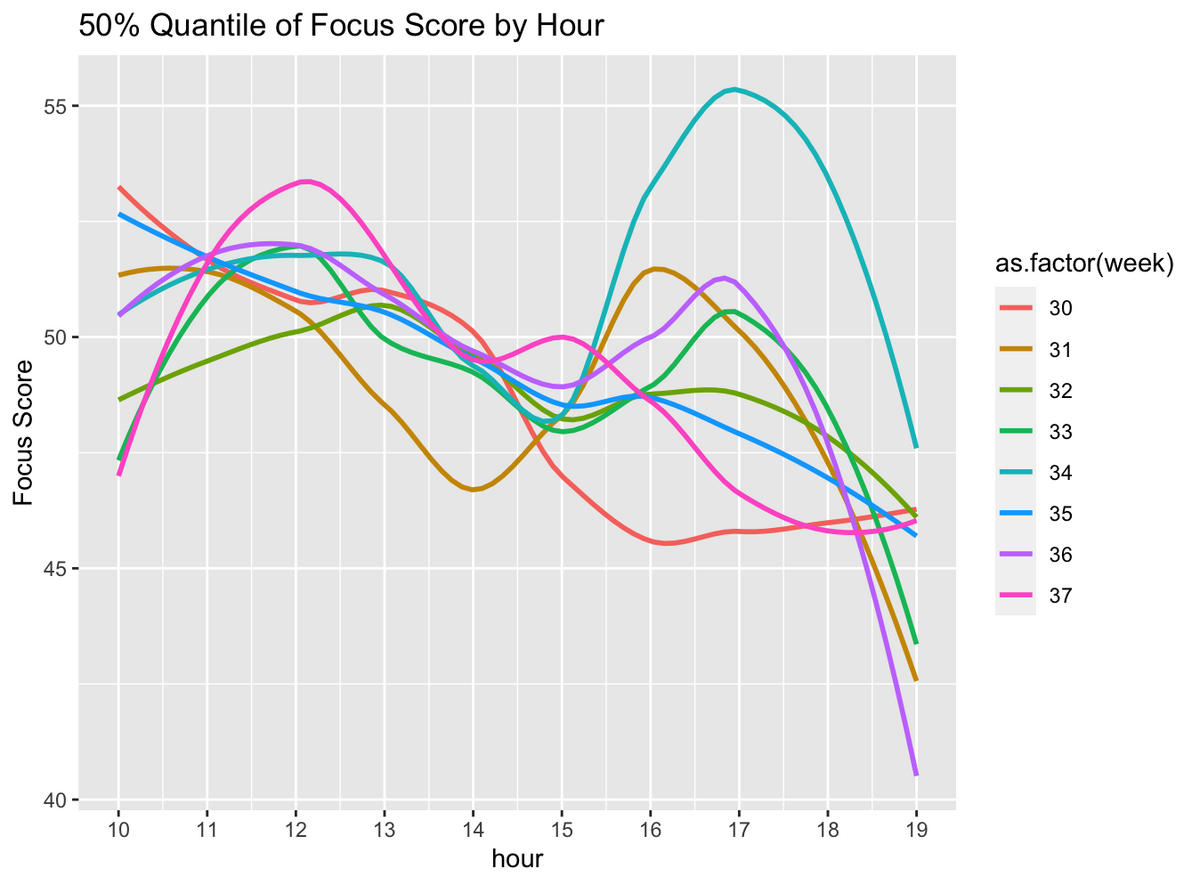
結構面白い図が書けました。集中度には2つ山があって、12-13時と16-17時で高くなっていそうな感じです
せっかくなのでもうちょっと見やすいように週ごとの曲線をまとめてみます
df.work.summary %>%
ggplot(aes(x = hour, y = sc_fcs_50)) +
geom_point() +
geom_smooth() +
scale_x_continuous(breaks = seq(10, 19, 1)) +
labs(title = "Boxplot of Focus Score by Hour",
x = "hour",
y = "Focus Score")
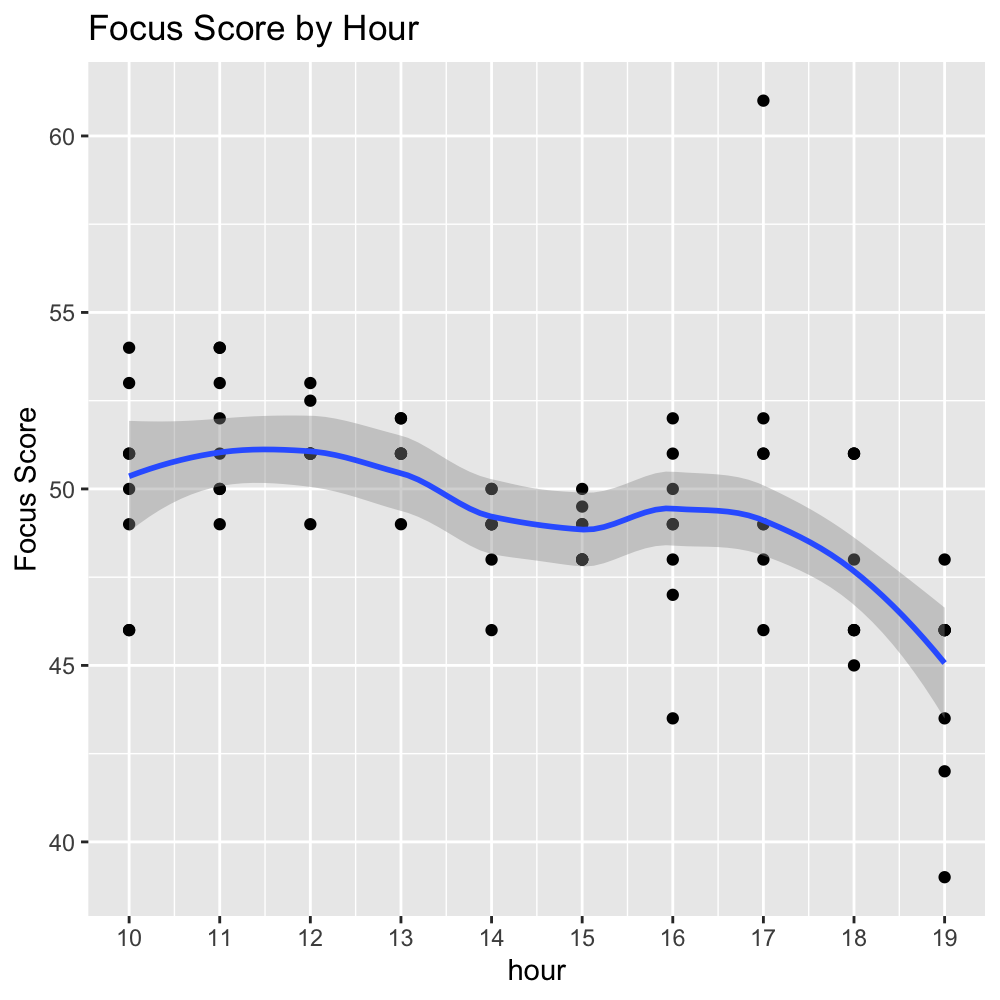
先ほどの図の考察で2つ山があると言いましたが、一方で大まかな傾向としては午前中の方が午後よりも集中力が高いようです
私は以前朝方夜型診断というものをやったことがあって、結果は中間型(偏差値50)だったのでエンジニア界隈では珍しく?午前中が一番捗るタイプのようです
感想
今回は R で JINS MEME のデータを使って遊んでみました
メガネ型のウェアラブルデバイスとしてはかなり先駆的な製品なのでセンサーの精度など正直あまり期待してなかったのですが、自分でも結構納得の結果が出て驚いています
自分が朝方か夜型か知りたい人は是非ともかけてみてください
この分析を通してメガネ愛が強まった人にはこちらの商品もおすすめです
suzuri.jp